

-
Les systèmes de stockage de données sont les actifs informatiques les plus attaqués
Bien que les environnements infonuagiques offrent des mesures de sécurité strictes pour assurer la sécurité de vos données, les cyberattaques sophistiquées qui ciblent le modèle de responsabilité partagée du nuage sont en hausse.
-
4 stratégies clés de reprise après sinistre pour votre infrastructure infonuagique
Pour les clients qui tirent parti des charges de travail infonuagiques pour leurs données, nos partenaires d’AWS offrent des stratégies clés de reprise après sinistre visant à améliorer la résilience de leurs données.
-
Sauvegarde et restauration
Dans cette stratégie, vos données et configurations hébergées par AWS sont régulièrement sauvegardées et stockées dans un endroit fiable, ce qui signifie généralement un centre de données d’AWS d’une région différente. La reprise se fait simplement en rétablissant ces sauvegardes après une catastrophe.
-
Veilleuse
L'approche de la « veilleuse » permet de conserver une copie réelle des composants principaux de votre infrastructure AWS dans une région AWS différente, tandis que des composants supplémentaires sont maintenus inactifs jusqu'à ce qu'une catastrophe se produise.
-
Secours semi-automatique
Le secours semi-automatique implique une version réduite de votre environnement de production fonctionnant en continu. Lorsqu’une catastrophe survient, elle est rapidement mise à l’échelle jusqu’à sa pleine capacité de production et remplace toute ressource défaillante.
-
Multisite actif/actif
Cette stratégie implique l’exécution d’environnements à grande échelle identiques dans plusieurs emplacements. Chaque site est parfaitement capable de gérer la charge de travail en entier, garantissant que si un site tombe en panne, d’autres peuvent prendre le contrôle instantanément sans temps d'indisponibilité.
-
Commencer votre parcours de reprise après sinistre avec AWS et CDW
CDW tient lieu de partenaire de consultation estimé d'AWS avec une expertise et une expérience dans la conception, la mise en œuvre et la gestion de la sauvegarde et reprise après sinistre. Nous vous accompagnons dans votre parcours de reprise après sinistre afin d’atteindre les objectifs propres à votre organisation.
4 stratégies de reprise après sinistre pour vous rendre résilient aux cybermenaces en évolution
Dans ce blogue, nous discutons de la façon dont les décideurs des technologies de l’information peuvent utiliser des mesures de reprise après sinistre infonuagique pour protéger leur infrastructure. Nous nous penchons sur le paysage des cybermenaces et fournissons quatre stratégies clés offertes par nos partenaires chez AWS qui visent à assurer une meilleure reprise après sinistre.


Dans un scénario de cyberattaque, vos données sont l’actif informatique le plus difficile à récupérer. Surtout si elles sont compromises, chiffrées ou détruites lors de l’attaque.
Sachant bien cela, les cyberattaquants ont commencé à cibler les systèmes de stockage de données dans l’ensemble des organisations canadiennes avec une plus grande sophistication. Our 2024 Étude canadienne sur la cybersécurité de CDW found that public cloud, which is used for data-intensive workloads, had the largest share of such attacks.
Compte tenu de ce scénario, les mécanismes standard de sauvegarde et de restauration des données peuvent ne pas offrir une protection complète aux organisations ayant des investissements dans le nuage. Ces dernières ont besoin d’une stratégie de reprise après sinistre bien conçue qui peut se défendre contre les cybermenaces et renforcer la résilience des données.
Dans ce blogue, nous discutons de la façon dont les décideurs des technologies de l’information peuvent utiliser des mesures de reprise après sinistre infonuagique pour protéger leur infrastructure. Nous nous penchons sur le paysage des cybermenaces en évolution et fournissons quatre stratégies clés offertes par nos partenaires chez AWS qui visent à assurer une meilleure reprise après sinistre.
Les systèmes de stockage de données sont les actifs informatiques les plus attaqués
Our 2024 Étude canadienne sur la cybersécurité de CDW observed the impact of cyberattacks across the various assets contained in a typical IT environment. L’étude a révélé que le nuage public était l’actif informatique le plus touché, avec 56,7 pour cent des entreprises signalant des cyberattaques en 2024, en hausse par rapport à 43,5 pour cent en 2022.
En même temps, la quantité de systèmes de stockage d'entreprise touchés est également passée de 25,2 pour cent à 31,6 pour cent entre 2022 et 2024.
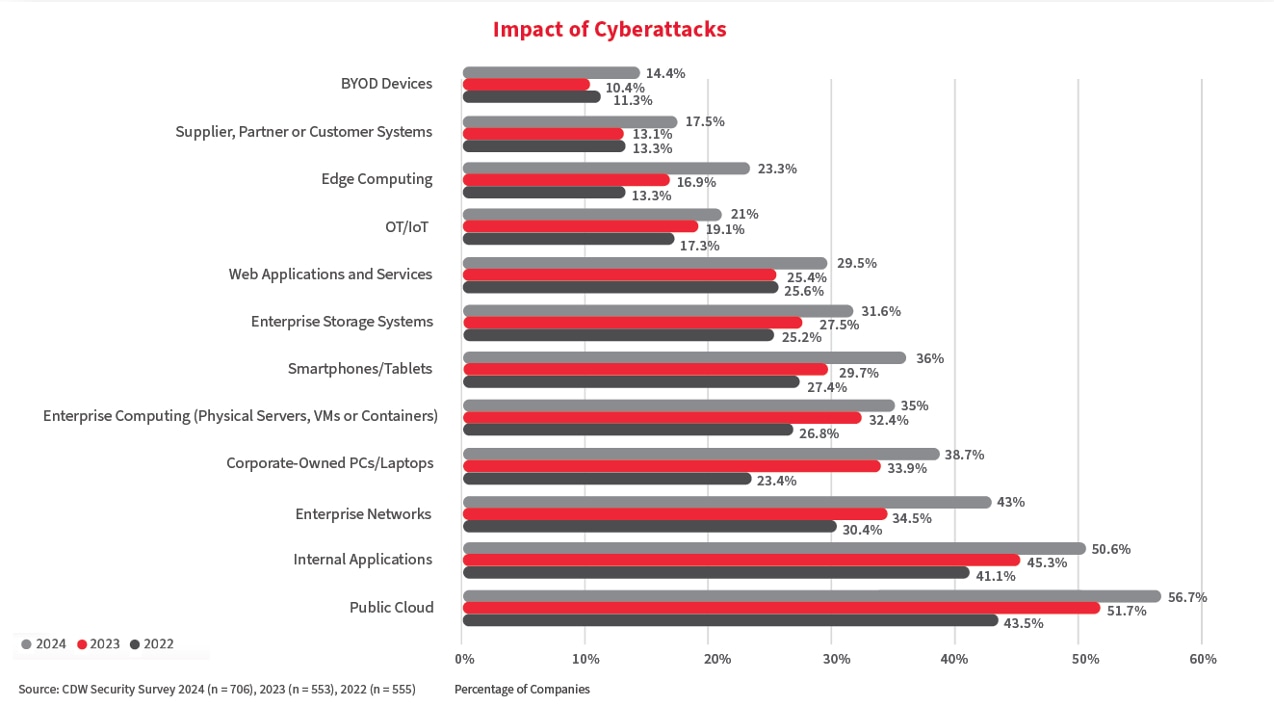
Bien que les environnements infonuagiques offrent des mesures de sécurité strictes pour assurer la sécurité de vos données, les cyberattaques sophistiquées qui ciblent le modèle de responsabilité partagée du nuage sont en hausse. Plutôt que de violer la sécurité du fournisseur de services infonuagiques, les pirates peuvent tenter de voler vos identifiants d’administrateur ou d’exécuter des attaques par rançongiciel qui peuvent mettre vos défenses internes en danger.
Ces tendances indiquent qu’à l’avenir, de plus en plus d’organisations pourraient être confrontées à des cyberattaques plus fréquentes de leurs systèmes de stockage, ce qui rend essentielle la mise en place d’une stratégie robuste de sauvegarde des données.
La reprise après sinistre et les sauvegardes peuvent devenir complexes
Une stratégie de reprise après sinistre ne se limite pas à la création d’une copie sécuritaire de vos données. Elle comprend une liste d’objectifs de récupération et un contrat de niveau de service (ou contrat SLA) pour vous assurer que vos données restent résilientes, notamment :
- Récupérer la bonne quantité de données au bon moment
- La vitesse de reprise doit répondre aux exigences de l’entreprise
- Les données sauvegardées doivent être protégées contre les dommages et la corruption
- Les sauvegardes doivent se trouver dans un endroit isolé
- L’accès et l’autorisation appropriés doivent être configurés
- L’infrastructure doit être rétablie à un état opérationnel donné lors de la reprise
Si vos données sont hébergées à l’aide d’une combinaison de ressources infonuagiques et sur place, atteindre les objectifs de sauvegarde et de récupération peut devenir encore plus difficile. Les équipes informatiques doivent souvent élaborer une stratégie minutieuse pouvant harmoniser les éléments logistiques de la sauvegarde constitués d’environnements, de coûts de stockage, de risques causés par des tiers et de frais généraux techniques disparates.
4 stratégies clés de reprise après sinistre pour vos actifs infonuagiques
Pour les clients qui tirent parti des charges de travail infonuagiques pour leurs données, nos partenaires d’AWS offrent des stratégies clés de reprise après sinistre visant à améliorer la résilience de leurs données.
Ces stratégies permettent aux praticiens en nuage de planifier de manière transparente comment configurer les services AWS, affecter des ressources et automatiser les sauvegardes dans leur architecture système. Chaque stratégie est conçue pour servir un scénario de reprise après sinistre différent en fonction des actifs qu’ils veulent sauvegarder et de la rapidité avec laquelle ils veulent les récupérer.
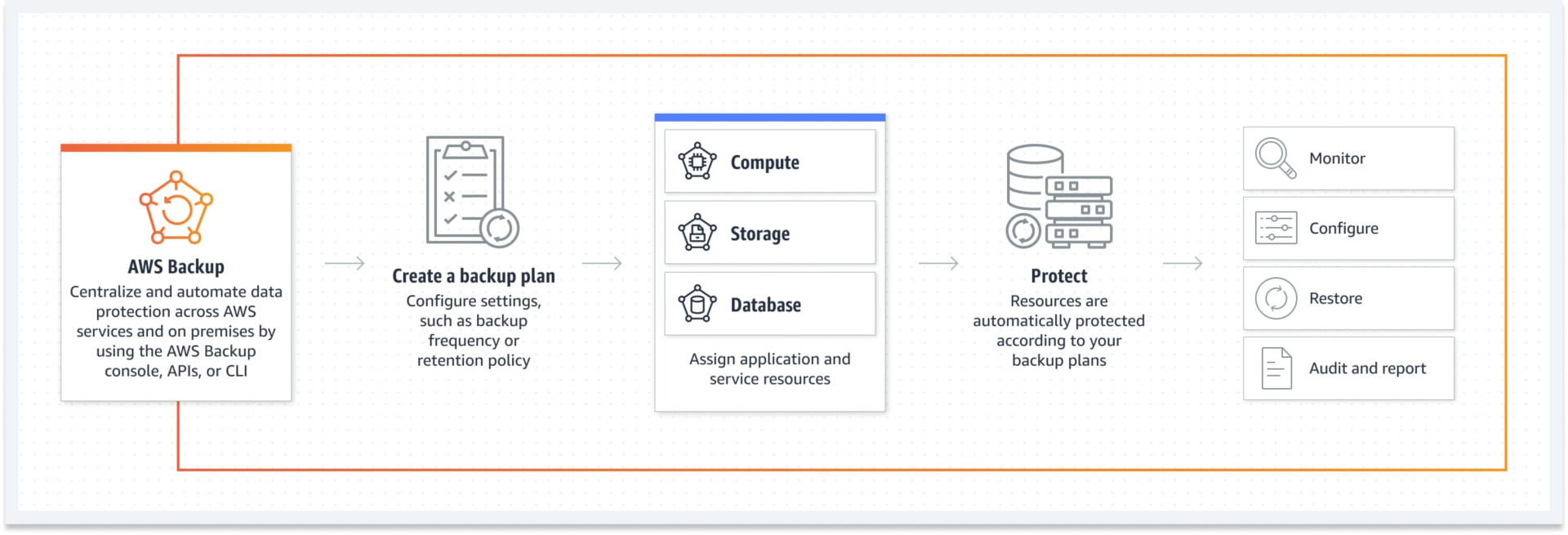
1. Sauvegarde et restauration
Dans cette stratégie, vos données et configurations hébergées par AWS sont régulièrement sauvegardées et stockées dans un endroit fiable, ce qui signifie généralement un centre de données d’AWS d’une région différente. La reprise se fait simplement en rétablissant ces sauvegardes après une catastrophe.
La stratégie fournit un mécanisme de sauvegarde de vos volumes EBS, instances EC2, bases de données RDS et instantanés EFS, entre autres ressources, à l'aide du service de sauvegarde AWS Backup.
Comment effectuer la conception
L'architecture implique le service AWS Backup, AWS S3 et une région AWS supplémentaire pour la duplication. Le service de sauvegarde offre un plan de contrôle centralisé permettant de configurer les sauvegardes à l’échelle des ressources d’AWS. Les praticiens peuvent élaborer des plans et des politiques de sauvegarde continue pour leurs charges de travail les plus critiques.
Les données sont sauvegardées sur des services AWS comme S3 ou S3 Glacier qui sont reproduits dans la nouvelle région. En cas de catastrophe, ces sauvegardes sont restaurées et les systèmes sont réapprovisionnés à partir de la région distincte.
Note : Bien que le service offre l’automatisation de sauvegarde, la récupération doit être automatisée à l’aide des appels API supplémentaires qui peuvent être configurés à l’aide d’AWS Rapha et d’AWS SNS.
Scénarios couverts
Cette solution est bien adaptée aux applications non critiques ayant des besoins réduits en matière de temps de disponibilité, comme les environnements de développement, les plateformes de partage de fichiers ou les services de courriel, où des temps d’indisponibilité occasionnels sont acceptables. L’objectif de temps de reprise (OTR) et l’objectif de point de reprise (OPR) ont tendance à être plus longs, selon les intervalles de sauvegarde et la complexité du processus de restauration.
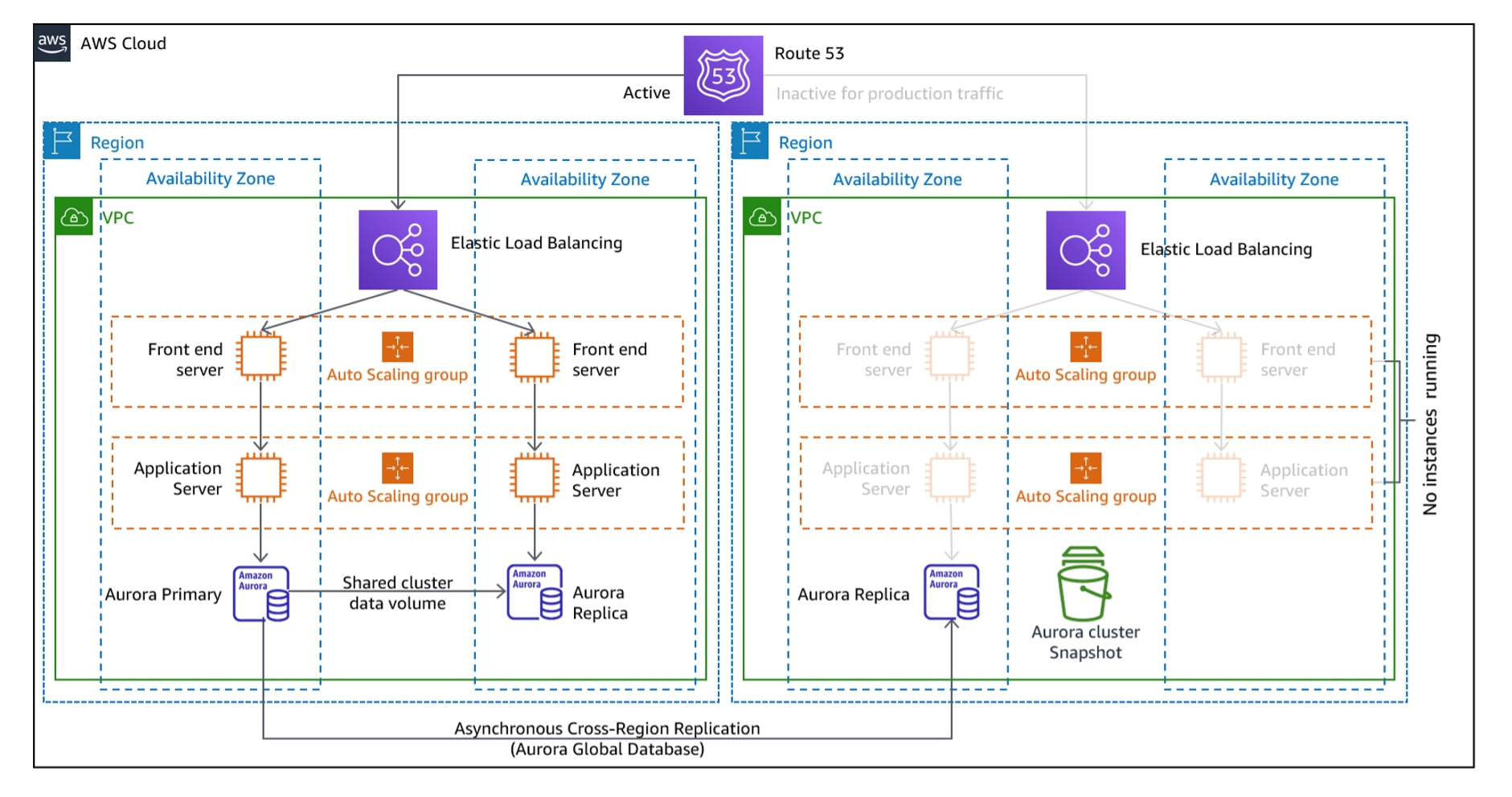
2. Veilleuse
L'approche de la « veilleuse » permet de conserver une copie réelle des composants principaux de votre infrastructure AWS dans une région AWS différente, tandis que des composants supplémentaires sont maintenus inactifs jusqu'à ce qu'une catastrophe se produise.
Imaginez pouvoir bénéficier de l’avantage d’une version dupliquée, mais partiellement fonctionnelle, de votre architecture infonuagique toujours prête dans une autre région. Vous pouvez l’activer complètement au besoin et vos données sont activement dupliquées dans la région de sauvegarde.
Comment effectuer la conception
L’architecture repose sur la duplication des données et la mise à l’échelle rapide des ressources de réserve inactives.
La duplication des données interrégionales (entre la région principale et la région de sauvegarde) est réalisée en utilisant :
- Réplication Amazon S3
- Réplicas en lecture Amazon RDS
- Base de données globale Amazon Aurora
- Tables globales Amazon DynamoDB
Alors que les ressources dormantes prennent vie rapidement grâce à Auto Scaling AWS et l'équilibreur de charge Elastic Load Balancing AWS
Les services de base (comme une base de données) fonctionnent toujours avec un minimum de ressources informatiques, comme une instance RDS. Les serveurs d'applications ou autres parties non critiques de l'environnement sont inactifs (p. ex. dans les instances EC2 arrêtées). La stratégie est conçue de manière à ce que, lorsqu’une catastrophe se produit, l’infrastructure puisse être rapidement mise à l’échelle jusqu’au niveau de production.
Scénarios couverts
La « veilleuse » fonctionne bien pour les systèmes qui ont besoin d’une récupération plus rapide que la sauvegarde, mais qui ne nécessitent pas de redondance à temps plein, comme les plateformes de commerce électronique où un accès rapide à la base de données est nécessaire, mais qui peuvent se permettre de mettre à l’échelle les applications Web ou tierces plus tard. Elle permet une récupération plus rapide par rapport aux méthodes offrant la sauvegarde seulement avec un coût plus gérable.
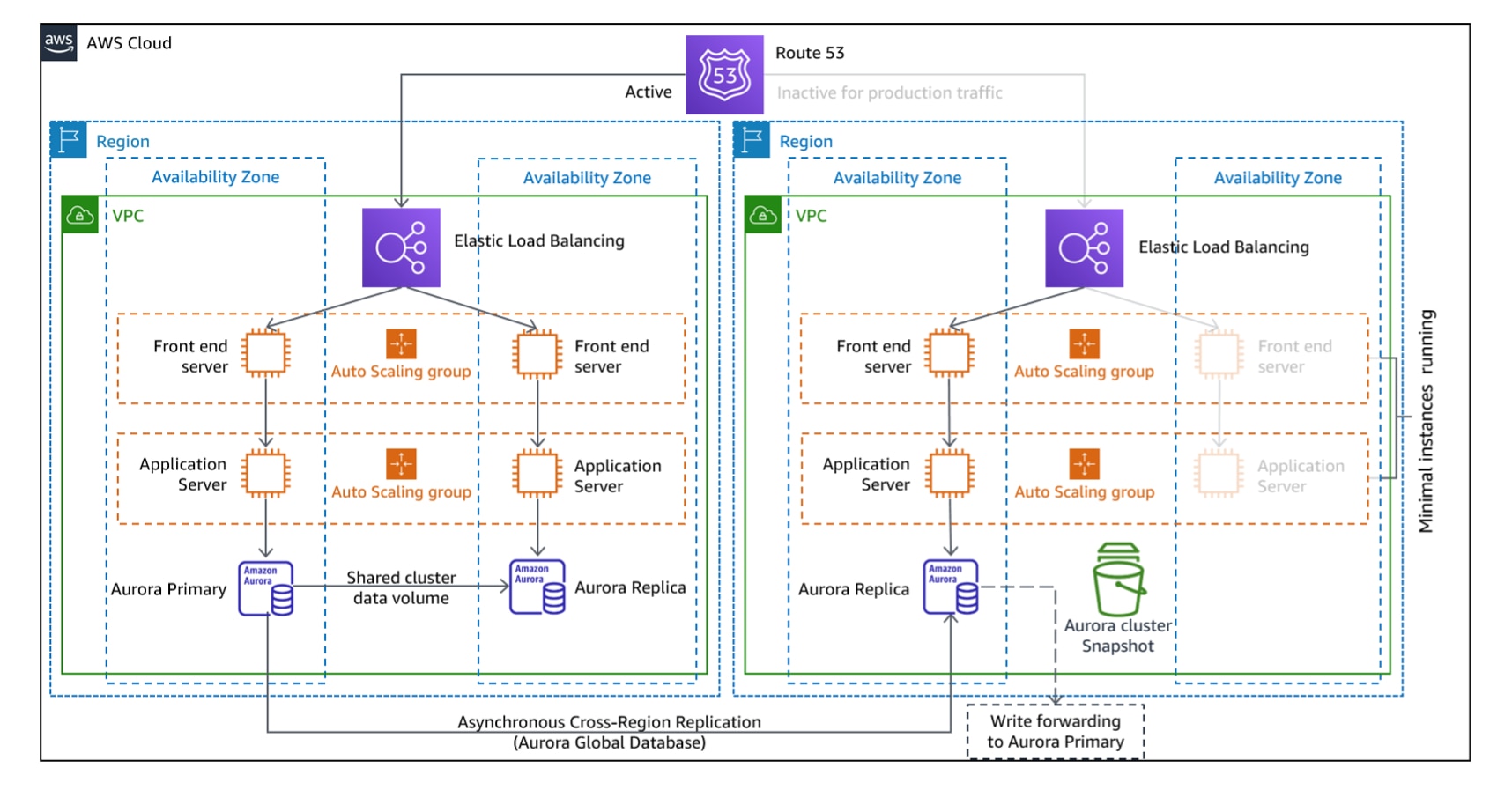
3. Secours semi-automatique
Le secours semi-automatique implique une version réduite de votre environnement de production fonctionnant en continu. Lorsqu’une catastrophe survient, elle est rapidement mise à l’échelle jusqu’à sa pleine capacité de production et remplace toute ressource défaillante.
Cette stratégie, contrairement à la « veilleuse », maintient un double de l’ensemble de l’architecture dans un état opérationnel. Par conséquent, elle peut rapidement passer à l’action au besoin, offrant un mécanisme à haute vitesse permettant de récupérer l’infrastructure et prévenir la perte de données.
Comment effectuer la conception
Cette stratégie exige que vous construisiez un environnement de réserve, qui communique avec l’environnement principal en utilisant les mêmes services de duplication que l’approche de la « veilleuse ». La façon la plus rapide de créer l’environnement de copie est d’utiliser les modèles AWS CloudFormation avec IaC. Cela peut simplifier la tâche complexe de réapprovisionnement des services.
En cas de catastrophe, les composants de l’environnement de copie peuvent être adaptés pour répondre aux demandes de production en utilisant AWS Elastic Beanstalk, Auto Scaling ou en mettant à l’échelle les types d’instances dans AWS RDS.
- AWS EC2 (version réduite) : pour exécuter des applications en mode veille.
- AWS RDS (instance plus petite) : pour les opérations de base de données.
- Auto Scaling AWS, Elastic Beanstalk : pour la mise à l’échelle des services au besoin.
- AWS Route 53 : pour le routage DNS vers l’environnement de veille.
Scénarios couverts
Convient aux applications critiques où les temps d'indisponibilité doivent être minimisés, mais pas complètement éliminés, comme les applications en logiciel-service (SaaS) où la disponibilité des utilisateurs est importante, mais peut entraîner de brèves perturbations. Il offre un objectif de temps de reprise (OTR) et un objectif de point de reprise (OPR) inférieurs à ceux de l’approche de la « veilleuse » ainsi que des stratégies de sauvegarde et de restauration.
4. Multisite actif/actif
Cette stratégie implique l’exécution d’environnements à pleine échelle identiques dans plusieurs emplacements (régions) qui desservent activement le trafic. Chaque site est parfaitement capable de gérer la charge de travail en entier, garantissant que si un site tombe en panne, d’autres peuvent prendre le contrôle instantanément sans temps d'indisponibilité.
La deuxième réplique de l’environnement principal sert activement le trafic des utilisateurs et agit comme une copie en temps réel à laquelle vous pouvez accéder à tout moment sans avoir à attendre. Il existe une autre version de la même stratégie appelée veille active passive/active, qui possède également un environnement de veille à pleine échelle, mais celle-ci n’est pas utilisée pour desservir le trafic en direct.
Comment effectuer la conception
L’architecture de cette stratégie est la plus difficile à réaliser en raison de multiples environnements à pleine échelle. Les organisations peuvent garder plusieurs régions actives en créant d’abord des répliques d’infrastructure à l’aide d’AWS CloudFormation pour simplifier le processus de reconstitution.
- Des services comme AWS CloudFormation StackSets peuvent aider à améliorer la gestion de plusieurs environnements déployés dans l’ensemble des régions.
- AWS Global Accelerator peut également être utilisé pour contrôler le pourcentage de trafic que chaque site actif doit gérer. En combinaison avec AWS Route 53, qui gère le système DNS, les deux sites peuvent atteindre une disponibilité transparente.
- Les instances actives s'exécutent simultanément dans les régions AWS.
- Des services comme Route 53 peuvent gérer la distribution du trafic et les contrôles de santé pour s’assurer que tous les sites fonctionnent correctement.
- Si une région échoue, le trafic est automatiquement acheminé vers une autre.
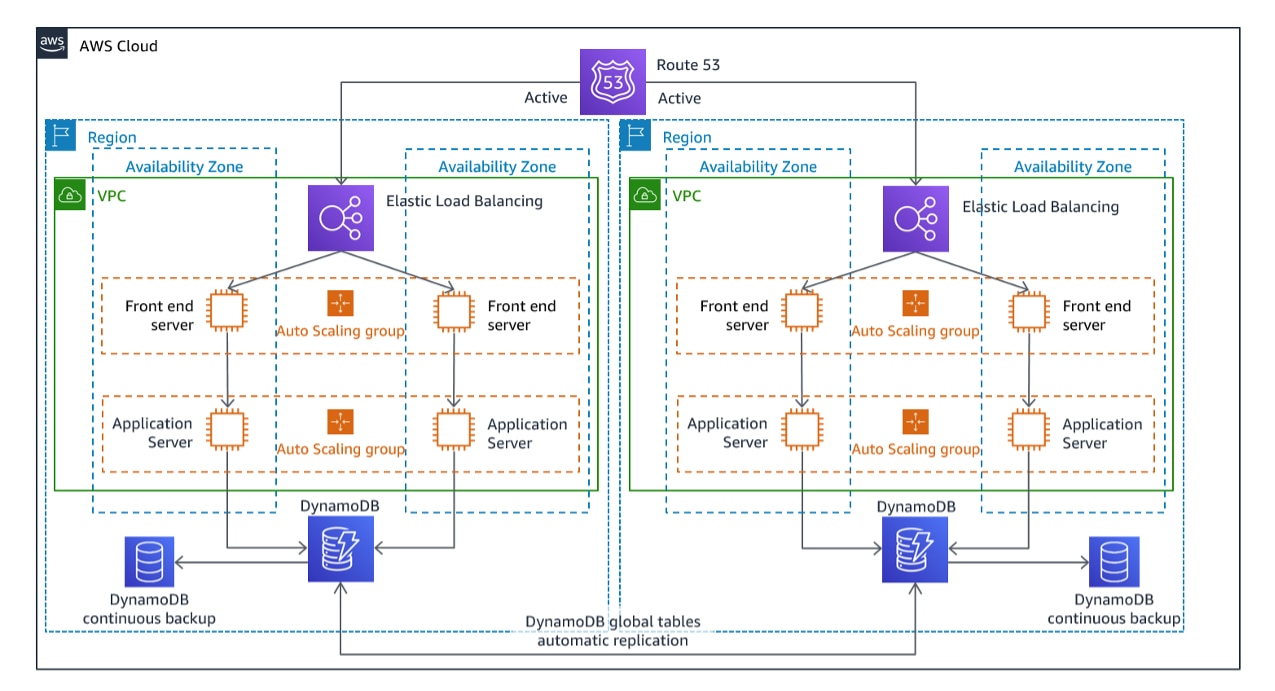
Scénarios couverts
Cette stratégie est la mieux adaptée aux applications essentielles à la mission où l’absence de temps d'indisponibilité est requise, comme les banques, les services financiers et les plateformes de commerce électronique mondial. Elle offre l’objectif de temps de reprise (OTR) et l’objectif de point de reprise (OPR) les plus bas, assurant une haute disponibilité même en cas de défaillances régionales.
Commencer votre parcours de reprise après sinistre avec AWS et CDW
Que vous prévoyiez migrer vos charges de travail de données vers le nuage ou que vous utilisiez déjà les services AWS, il est important de disposer d’un plan de résilience des données pour vous prémunir des cyberincidents.
CDW tient lieu de partenaire de consultation estimé d'AWS avec une vaste expertise et une expérience dans la conception, l’implémentation et la gestion de solutions de récupération après sinistre.
Nous vous accompagnons dans votre parcours de reprise après sinistre afin d’atteindre les objectifs propres à votre organisation. Qu’il s’agisse de tests de sauvegarde, de restauration ou de surveillance des données, nous nous assurons que vos données sont toujours protégées et accessibles.
En vous associant à CDW et AWS, vous pouvez aider votre organisation à :
- Réduire les coûts de reprise après sinistre : Économisez considérablement sur les coûts de sauvegarde et de reprise après sinistre en utilisant les services infonuagiques de paiement à l’utilisation d’AWS associés aux licences d’experts de CDW.
- Répondre à vos besoins en matière d’extensibilité : Augmentez ou réduisez facilement vos ressources de sauvegarde et de reprise après sinistre, selon le volume et la fréquence de vos données. Nos experts AWS vous aident à structurer votre environnement infonuagique pour vous assurer qu’il reste extensible.
- Sécuriser vos sauvegardes : Protégez vos données contre tout accès ou toute modification non autorisés en utilisant les fonctionnalités de sécurité AWS, gérées par nos experts en sécurité des données.
- Atteindre vos objectifs de récupération : Assurez-vous que toutes vos données peuvent être rapidement récupérées conformément à vos objectifs de temps de reprise (OTR) et objectifs de point de reprise (OPR) prédéfinis grâce à notre support de configuration de services AWS.
- Assurer la conformité : Nos architectes de solutions AWS certifiés conseillent les clients en fonction du cadre de travail AWS Well Architected (WAF), qui s’assure que leurs stratégies sont alignées sur les meilleures pratiques.
Fort de deux décennies d’expérience sur le marché canadien et disposant d’une équipe dévouée de plus de 80 architectes de solutions infonuagiques à l’échelle nationale, nous sommes bien équipés pour répondre à vos exigences en matière de résilience des données. Notre modèle d’évaluation, d’architecture, de mise en œuvre et d’exploitation assure une gestion complète de vos besoins en matière de protection et de résilience des données.
Nos solutions de récupération après sinistre assurent une récupération rapide de vos données, une protection évolutive et des conseils d’experts, ce qui fait de nous l’un des principaux partenaires AWS au Canada, grâce à des compétences de bout en bout.